



Un nuevo enfoque en el aprendizaje automático: el aprendizaje auto-supervisado contextual
El campo del aprendizaje automático se ha caracterizado tradicionalmente por dos categorías principales: el aprendizaje supervisado y el no supervisado. En el aprendizaje supervisado, los algoritmos se entrenan con datos etiquetados, donde cada entrada se asocia con una salida correspondiente, facilitando así la guía del algoritmo. Por otro lado, el aprendizaje no supervisado se basa únicamente en datos de entrada, lo que obliga al algoritmo a descubrir patrones o estructuras sin ninguna salida etiquetada. Sin embargo, en los últimos años ha surgido un nuevo paradigma conocido como «aprendizaje auto-supervisado» (SSL), que difumina las líneas entre estas categorías tradicionales.
El aprendizaje auto-supervisado elimina la dependencia de expertos humanos para etiquetar datos, lo que se convierte en un proceso costoso y laborioso. En lugar de ello, los algoritmos de SSL generan automáticamente etiquetas a partir de datos en bruto. Este enfoque se aplica en diversas áreas, como el procesamiento del lenguaje natural, la visión por computadora y el reconocimiento de voz. Las técnicas de SSL convencionales suelen fomentar que las representaciones de pares semánticamente similares estén cerca entre sí, mientras que las de pares disímiles se encuentren más alejadas. No obstante, la imposición de invariancia o equivarianza a un conjunto predefinido de aumentos introduce fuertes «prioris inductivos», que son suposiciones inherentes sobre las propiedades que las representaciones aprendidas deben satisfacer, y que no son universales para una variedad de tareas posteriores.
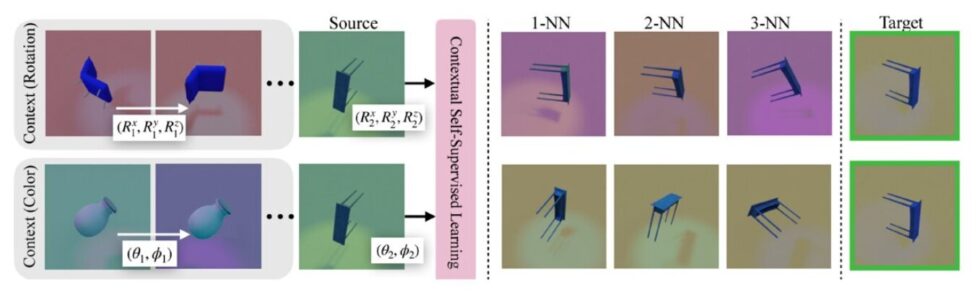
Investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT y de la Universidad Técnica de Múnich han propuesto un nuevo enfoque en el aprendizaje auto-supervisado, denominado «Aprendizaje Auto-Supervisado Contextual» (ContextSSL). Este método aborda las limitaciones de depender de aumentos predefinidos, al aprender de una representación general que se adapta a diferentes transformaciones mediante la atención al contexto. Este contexto representa una noción abstracta de tarea o entorno, permitiendo así la creación de representaciones de datos más flexibles y adaptables a diversas tareas posteriores, eliminando la necesidad de reentrenamientos repetitivos para cada tarea. A través de experimentos exhaustivos en varios conjuntos de datos de referencia, los investigadores han demostrado la efectividad de ContextSSL, que permite que el modelo adapte dinámicamente sus representaciones en función de la tarea en cuestión.



